The number of games required for statistical significance in playtesting a single matchup is extremely large, and your sample size is probably insufficient.
From my 20 years of playing Magic, I have noticed an extremely strong correlation between mathematically inclined individuals and being entrenched in Magic: the Gathering. Naturally, this leads to an abundance of discussions about all forms of data about and around Magic. From card prices to deck popularity to matchup win percentages any data that is available to Magic players is subject to scrutinous analysis. Today we are going to discuss how to leverage the available data to complement experience-driven development and theory-driven development to round out your tournament preparation.
What is Data-Driven Development?
For this article and this series, data-driven development refers to using any amount of collected data to influence your deck building, deck selection, and deck tuning. In the times before the internet, this process would include the data collection step as well, but well into the booming age of the internet, tools like MTGGoldfish and EDHREC exist to collect and present a vast majority of the data desired by tournament grinders and casuals alike. As such, much of the knowledge surrounding how the collection of Magic data is simply knowing what tools to use and what the limitations of those tools are. The latter half is especially important, as additional limitations have been applied as time has gone on because WOTC felt things were getting “solved” too quickly due to the abundance of information available and has at multiple points directly restricted the data available to the public.
Much of the data that is used to dictate bans in formats that exist on Magic Online is completely hidden from the public despite being cited in the banning articles. While it can be argued some public perception issues may also have a hand in the decision to restrict data available to the community at large, it is also clear that having access to more data makes tournament preparation easier because you are far more informed when making deck adjustments. Because of this, it is also common for less experienced players to use data to conclude the scope of what the data indicates, a behavior shared by many other disciplines outside of the gaming world as well.
The Misuse Of Data
Statistics and data at large are rather infamous for misuse as the meteoric rise of the internet and, subsequently, powerful data collection and analysis tools have led to unprecedented information to inform decision-making. Among the most famous is the highlighted difference between correlation and causation, as inexperienced data analyzers mistake correlation with causation specifically quite often to the extent the topic is covered at length at multiple points in my schooling experience and there are dedicated websites to showing how extreme correlations can get and still have nothing to do with each other. All of this applies directly to Magic: the Gathering as well. Particularly in competitive formats and tournaments, where there are heavy incentives to “solve” or “break” the format of any given event.
The most striking example throughout my career of 60-card Magic has been matchup win percentages. The entire language around matchups and how they play out among many players is arbitrary win percentages. Matchups are often described as “50%” matchups, “55%” matchups, “60%” matchups, and so on all with wildly insufficient data to support these claims, as Karsten famously outlines here. The purpose the language serves in the community is a shorthand to indicate approximately how good or bad a particular matchup is in that individual's opinion. Despite being presented as a tangible percent chance to win a given matchup, there is no true mathematical backing behind most players' claims of matchup win percentage at all! Some players take this notion to the extreme however, and begin tracking their personal win rates in various matchups on personal spreadsheets over a long period or simply play a relatively large but statistically small amount of games of the matchup to prove that it is in fact as good or bad as advertised.
This approach faces numerous issues as Magic data decays over time as the metagame shifts and players learn and iterate more in each format. This is simply among the most common examples, and I have noticed the beginnings of this exact trend in cEDH as well, where instead of tracking specific matchup data due to the complexity of tracking such a thing in a multiplayer environment, players track their personal win rates on various decks to prove some combination of personal proficiency and/or deck potency with “undeniable evidence” to back their claims. However again due to the abundance of variables concerning pilot skill, opponent skill, specific card inclusions/exclusions, approach to matchups, and current metagame perceptions, this data does not compound on itself and is largely worse than useless when making assertions.

Data-Driven Development in cEDH
So if most data, especially in cEDH, is too small to draw infallible conclusions from, how do you use it effectively? The answer depends on the questions you are asking, and the best approach is to ask the smallest questions possible. If you want to know how commonly played the card Opposition Agent is, you can reasonably do so by evaluating data from sources like cedh.guide and EDH Top 16 to see how often the card has been included and decks and how often those decks have made deep runs in events. These kinds of questions that are small in scope are easily answered, and good questions to ask when evaluating things like whether you want Snuff Out or Dismember in your removal spell suite by the valuable targets each option hits as a function of that target’s popularity. Small-scoped, bite-sized questions like that are easy to answer with relatively small margins of error. Knowing how much your deck specifically cares about each creature that is played in the format and how difficult the spell is to cast are largely the only other variables to account for after using data to evaluate whether or not the removal spell is worth including so there is a low risk of making faulty decisions based on incorrect assumptions.
The bigger the question gets the more data is required, the more assumptions have to be made, and the more likely that your conclusion is at best flawed at worst entirely incorrect. If you wanted to know how often the Tivit, Seller of Secrets deck wins pods that include at least one Najeela, the Blade-Blossom deck you would need not only a massive amount of data from a variety of sources to assess this, but the conclusion is so broad that there is little tangible value to be gained from even getting a definitive answer to that question. It is completely possible that once you get an answer to the question there is more work to do. Maybe the data says Tivit only wins 10% of the time with Najeela in the pod but wins 40% of the time in a pod that contains Najeela and Kinnan, Bonder Prodigy. Because the initial question is so broad, using data to extract an answer is difficult, risky, and frankly insurmountable with the data we even have access to in cEDH. When you have a big question like this you want to be answered, the best approach is to break it up into even smaller questions. Oftentimes this manifests as individual card comparisons as a basis for the theory.
Let’s say you are losing to a Najeela player a lot with Tivit and your initial question is whether Najeela is a bad matchup, you can break this question down into specific problems. If the issue is that Najeela is just faster than you, are there adjustments that can be made to your removal suite to account for that? Maybe most Najeela decks also use Dockside Extortionist and Underworld Breach as critical contributors to the speed difference between Najeela and Tivit. Assuming this is the case, cards like Blue Elemental Blast and Hydroblast might be worth including in your removal suite to adjust for that. But you need to make cuts! Now you can assess which pieces of your removal suite have felt unnecessary based on the commonly played cards and strategies they were included to answer but were not necessary for doing so. This is again something you can use data for.
The key to successful data-driven development in cEDH is narrowing the scope of your questions to be the smallest they possibly can be. Often large questions are easily broken up into smaller ones when reflecting on what motivated you to ask the bigger question to begin with. Asking small enough questions and evaluating what the data is based on what is there and what is not there is the meat of the skill of data analysis in Magic and will not come naturally to most. As with anything, practice makes perfect, and an easy way I have found to practice is by starting with the data first. Instead of starting with a question you want answered, practice taking a look at a single tournament result and asking questions based on the results. What decks did well? What decks are absent from the elimination rounds? Are there any strange card inclusions or exclusions? What does the composition of the elimination rounds say about the event’s metagame? Did any of the players make choices based on a meta call or perception of the metagame that worked out? Any that didn’t work out? Once you have a set of questions and potential answers, you can compare those against other recent tournaments for potential trends you are seeing and leverage that. It is important not to put too much emphasis on a single result, however. Inexperienced players often overvalue winning an event compared to simply making the elimination rounds, where the reality is that the difference between making elimination rounds and winning is usually fairly small, and for the sake of data analysis the entire top 16, or top 8, can be evaluated as similarly performing.
Putting It All Together
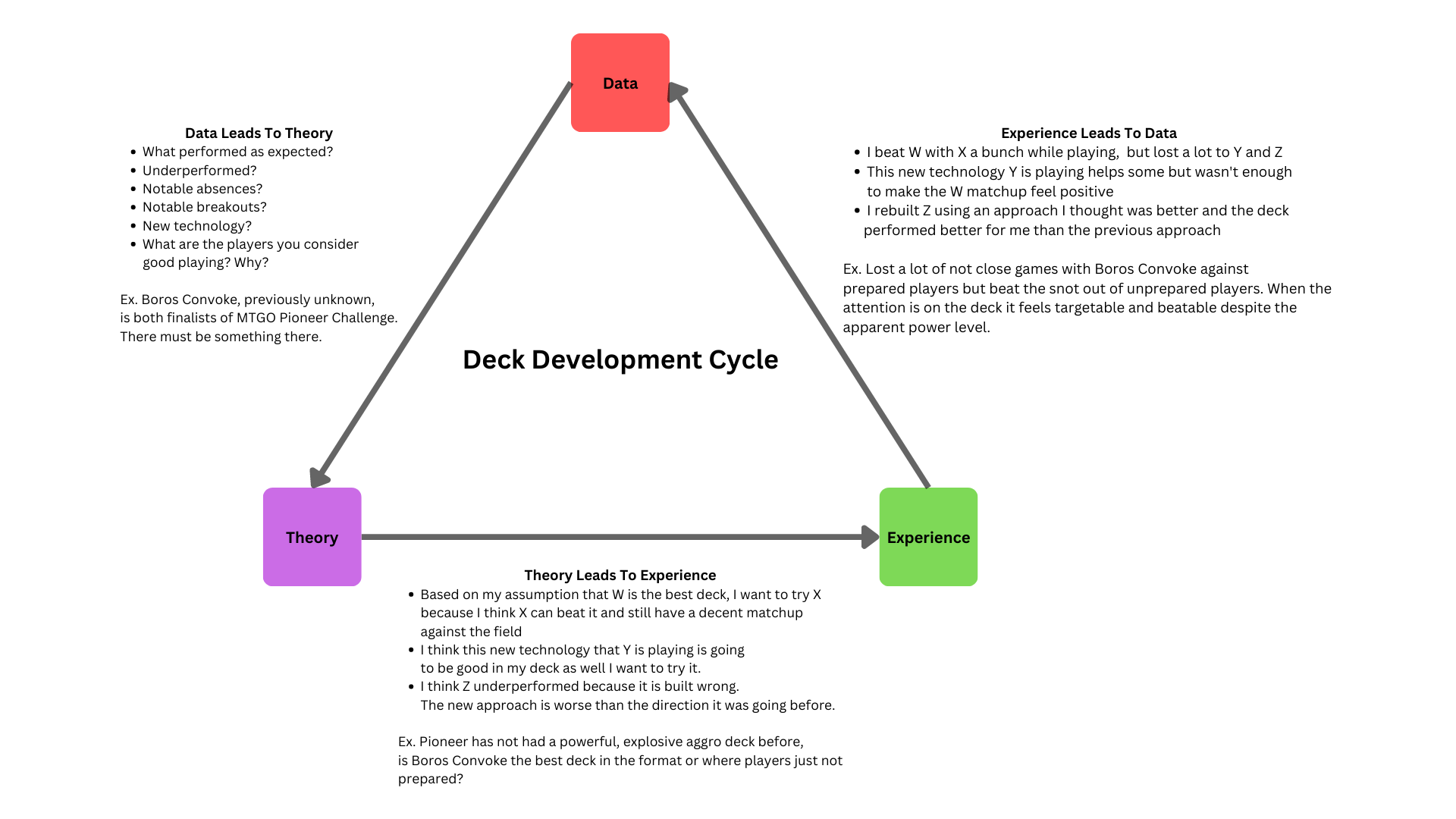
The application of data-driven development in cEDH and beyond is most effective alongside experience-driven development and theory-driven development, which I covered at length on this site in previous articles. While each is its own concept, I find they work best in tandem to provide a cohesive system for developing Magic decks. Through my experience as a part of tournament testing teams as well as my experience as a coach, I have found that striking the appropriate balance and relationship between all three of these concepts is extremely difficult.
Some players go too far on experiences and are only comfortable making assertions after playing hundreds of matches under their belt. Some go too far on theory, and rarely if ever play any games at all, making assertions only on their perceptions of how things will play out. Some go too far on data, and draw broad sweeping conclusions from small data sets, citing themselves as mathematically proven to be correct. Striking the balance in the relationship between all three of these approaches is critical for getting the closest to the truth that you possibly can get. Each aspect of the iteration process serves as a driver for another with the most common cycle being data driving the creation of theory which is then validated with experience and compared against new data. This concept can be a lot to grasp in text alone, which is why I created the graphic below to help illustrate the entire deck development cycle with an example of an interaction from recent pioneer data.
The examples provided in each step are just examples of the process and not even close to the extent of the possibilities. The power of this process is the flexibility in applications for each new circumstance and metagame configuration that is needed to prepare for. Learning and applying this system will revolutionize not just how you build decks and prepare for events of any stakes, but will also help you navigate discussions with other players to better leverage the data, theory, and experiences they have to offer. Thank you all for following along with this article series and let me know in the comments what you thought!

Comment
Join the conversation